# 예시 데이터프레임 생성 data = {'day': ['2021-11-30', '2021-12-01', '2021-12-02'], 'hour': [10, 11, 12]} df = pd.DataFrame(data)
# day열과 hour열을 문자열로 변환하고 공백을 추가하여 합친 후, pd.to_datetime 함수를 사용하여 datetime 타입으로 변환 df['dayhour'] = pd.to_datetime(df['day'].astype(str) + ' ' + df['hour'].astype(str))
# day열과 hour열을 문자열로 변환하고 합친 후, pd.to_datetime 함수를 사용하여 datetime 타입으로 변환하고 format 인자를 사용하여 형식을 지정 df['dayhour'] = pd.to_datetime(df['day'].astype(str) + df['hour'].astype(str), format='%Y-%m-%d%H:%M:%S')
# Attach body text = MIMEText(body) msg.attach(text)
# Attach file with open(attachment_path, 'rb') as file: attachment = MIMEApplication(file.read()) attachment.add_header('Content-Disposition', 'attachment', filename="abcd.txt") msg.attach(attachment)
# Connect to SMTP server and send email with smtplib.SMTP('smtp.gmail.com', 587) as server: server.starttls() server.login(send_email, send_pwd) server.sendmail(send_email, recv_email, msg.as_string())
# 사용 예시 send_email( send_email="보내는메일", send_pwd="비밀번호", recv_email="받는메일", subject="메일보내기 테스트입니다.", body="첨부파일과 함께 몌일 보내기.\n감사합니다.", attachment_path=r'c:\xxx\abcd.txt' )
# 이미지 파일 경로 icon_image_path = 'c:\\xxx.png' # 아이콘 파일의 위치를 설정
# 지도 생성 mymap = folium.Map(location=[37.7749, -122.4194], zoom_start=10)
# 사용자 지정 이미지를 마커에 설정 marker = folium.Marker( location=[37.7749, -122.4194], popup='This is a my custom marker', icon=folium.CustomIcon( icon_image_path, icon_size=(30, 30), icon_anchor=(15, 15), # 중심점 설정 (이미지의 중심으로 설정) popup_anchor=(0, -15) # 팝업의 위치 설정 ) )
# 마커를 지도에 추가 marker.add_to(mymap)
# 지도를 HTML 파일로 저장 mymap.save('map_with_custom_icon.html')
import pandas as pd
def read_and_filter_data(file_path, date_column, start_date, end_date):
"""
CSV 파일에서 데이터를 읽고 날짜를 기반으로 필터링하여 반환합니다.
"""
try:
df = pd.read_csv(file_path, parse_dates=[date_column])
df.set_index(date_column, inplace=True)
filtered_df = df.loc[start_date:end_date]
return filtered_df
except Exception as e:
print(f"Error reading or filtering data: {e}")
return None
# 파일 경로 및 날짜 범위 설정
file_path = 'your_data.csv'
date_column = 'date_column'
start_date = '2023-01-01'
end_date = '2023-01-31'
# 데이터 읽기 및 필터링
result_df = read_and_filter_data(file_path, date_column, start_date, end_date)
# 결과 확인
if result_df is not None:
print(result_df)
이 코드는 함수로 래핑하여 재사용 가능하게 만들었고, 에러 처리를 추가하여 예외 상황에 대비했습니다. 또한 주석을 추가하여 코드를 이해하기 쉽도록 했습니다.
코드를 함수로 래핑하고 에러 처리를 추가함으로써 코드의 재사용성과 유지보수성이 향상되었습니다. 함수를 통해 데이터 읽기 및 필터링이 일관되게 이루어지며, 예외가 발생할 경우 사용자에게 알리고 적절한 조치를 취할 수 있습니다.
함수에 추가적인 인자를 전달하면 더 많은 유연성을 확보할 수 있습니다. 예를 들어, 사용자가 날짜 형식을 지정하거나 다른 필터 기준을 추가할 수 있습니다. 반환값을 다르게 처리하여 실패 시에도 특별한 값을 반환하면 사용자에게 더 많은 정보를 제공할 수 있습니다.
추가적인 예외 처리를 위해 except Exception as e를 더 구체적인 예외로 세분화하는 것이 좋습니다. 예를 들어, pd.read_csv에서 발생하는 특정 예외를 잡아서 사용자에게 더 정확한 오류 메시지를 제공할 수 있습니다.
2. 코드 리뷰#2
또다른 예제 코드로 위의 내용을 바탕으로 구현한 코드입니다.
import pandas as pd
# Sample DataFrame with date range
df = pd.DataFrame({'date': pd.date_range(start='2023-01-01', periods=10, freq='D'),
'value': range(10)})
# Filtering data between specific dates
filtered_data = df[df['date'].between('2023-01-03', '2023-01-05')]
.between() 메소드 사용: 코드 간소화를 위해 .between() 메소드를 사용했습니다. 이는 가독성을 향상시키고 코드를 더 간결하게 만듭니다. 변수 이름: result 대신 filtered_data를 사용하여 결과의 의미를 명확히 합니다.
2. 위의 예제코드 시각화
시각화 코드 :
import pandas as pd
import matplotlib.pyplot as plt
# Sample DataFrame with date range
df = pd.DataFrame({'date': pd.date_range(start='2023-01-01', periods=10, freq='D'),
'value': range(10)})
# Filtering data between specific dates
filtered_data = df[df['date'].between('2023-01-03', '2023-01-05')]
# Plotting
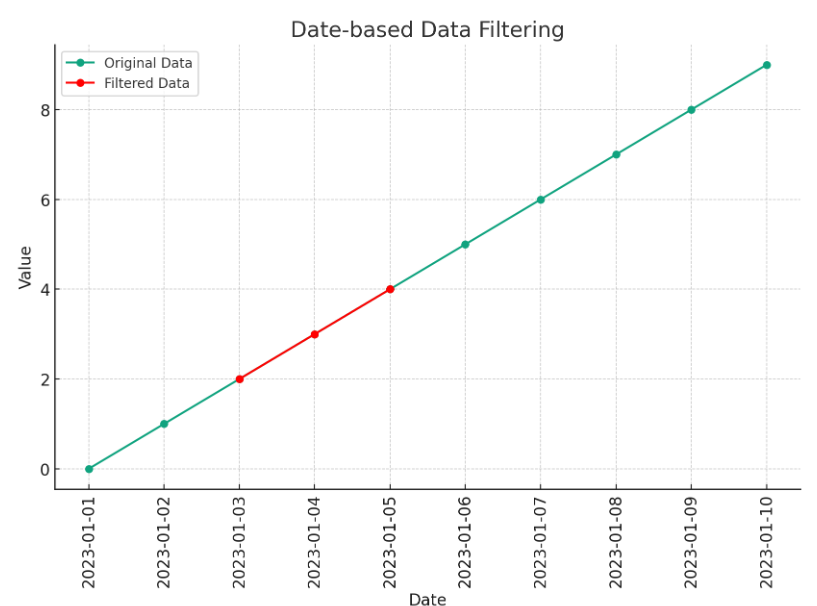
plt.figure(figsize=(10, 6))
plt.plot(df['date'], df['value'], label='Original Data', marker='o')
plt.plot(filtered_data['date'], filtered_data['value'], label='Filtered Data', marker='o', color='red')
plt.title('Date-based Data Filtering')
plt.xlabel('Date')
plt.ylabel('Value')
plt.xticks(rotation=90) # Rotate x-axis labels vertically
plt.legend()
plt.grid(True)
# Save the updated plot
plt.savefig('/mnt/data/date_filtering_plot_updated.png')
plt.show()
마무리
- 이번 포스팅은 판다스 데이터 프레임의 날짜형식 데이터 조건별 추출하는법 에 대해 알아봤습니다.
이 코드는 pandas를 사용하여 CSV 파일에서 데이터를 읽어와서 특정 날짜 범위에 해당하는 데이터를 추출하는 작업
1. 코드 리뷰
import pandas as pd
# CSV 파일 또는 다른 소스에서 데이터프레임을 읽어옴 (예: read_csv) df = pd.read_csv('your_data.csv', parse_dates=['date_column'])
# 특정 날짜 이후의 데이터 추출 start_date = '2023-01-01' filtered_df = df[df['date_column'] >= start_date]
# 특정 날짜 이전의 데이터 추출 end_date = '2023-01-31' filtered_df = df[df['date_column'] <= end_date]
위의 내용으로 정리한 코드
import pandas as pd
# 데이터 읽기
df = pd.read_csv('your_data.csv', parse_dates=['date_column'])
# 특정 날짜 범위 추출
start_date = '2023-01-01'
end_date = '2023-01-31'
# 조건을 합쳐서 한 번에 필터링
filtered_df = df[(df['date_column'] >= start_date) & (df['date_column'] <= end_date)]
두 번의 필터링을 하나로 합치면 코드가 간결해지고 가독성이 향상됩니다. 또한, 필터링된 데이터프레임을 생성하고 저장하는 데 필요한 메모리 및 연산 비용을 줄일 수 있습니다.
필터링된 데이터를 보존하는 방법은 여러 가지가 있습니다.
새로운 변수에 할당: 필터링된 데이터를 새로운 변수에 할당하여 원본 데이터를 보존할 수 있습니다. 복사: copy() 메서드를 사용하여 데이터프레임을 복사하고, 이후에 필터링을 적용합니다. 인덱싱: 필터링된 결과를 인덱싱하여 새로운 데이터프레임을 생성합니다.
def find_ordered_duplicates(list1, list2): duplicates = [] for item in list1: if item in list2 and item not in duplicates: duplicates.append(item) return duplicates
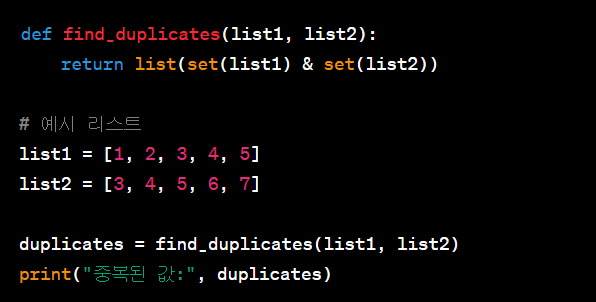
- 위의 코드에서는 set 자료형을 활용하여 각 리스트의 중복되지 않은 값들을 모두 제거하고, 그 후에 교집합 연산자 &를 사용하여 두 집합의 공통된 요소를 찾습니다. 이를 통해 중복된 값을 찾을 수 있습니다. 단, 이 방법은 중복된 값들을 순서대로 보존하지 않습니다. 중복된 값들을 보존하며 어떤 작업을 수행하려면 더 많은 로직이 필요할 수 있습니다.