728x90
반응형
티스토리
서로 다른 시계열 데이터프레임을 날짜 시간 순서로 병합(Merge)
Pandas 라이브러리는 데이터 조작 및 분석에 필수적인 도구입니다. 오늘은 Pandas를 사용하여 서로 다른 구조를 가진 두 데이터프레임을 날짜 및 시간을 기준으로 효과적으로 병합하는 방법을 탐구하겠습니다.
1. 코드리뷰
import pandas as pd
# 두 데이터프레임 생성
df1 = pd.DataFrame({
'date': pd.to_datetime(['2023-10-13 0:00', '2023-10-14 1:00', '2023-10-15 2:00',
'2023-10-16 3:00', '2023-10-17 4:00', '2023-10-18 5:00']),
'A1': [1, 2, 3, 4, 5, 6],
'B1': [3434, 1, 3, 45, 5, 675],
'Vendor': ['SAMSUNG', 'TESLA', 'TESLA', 'SAMSUNG', 'TESLA', 'SAMSUNG']
})
df2 = pd.DataFrame({
'date': pd.to_datetime(['2023-10-13 0:00', '2023-10-14 1:00', '2023-10-15 2:00',
'2023-10-16 3:00', '2023-10-17 4:00', '2023-10-18 5:00']),
'A1': [4, 8, 3, 5, 3, 2],
'B1': [3434, 1, 3, 45, 5, 675],
'Vendor': ['LG', 'KIA', 'TESLA', 'SAMSUNG', 'BMW', 'SAMSUNG'],
'C2': ['JK1', 'JK3', 'JK5', 'DH3', 'LK2', 'MN2']
})
# 데이터프레임 병합 및 날짜 시간 순서 정렬
merged_df = pd.concat([df1, df2]).sort_values(by='date')
병합하기전 두개의 다른 데이터 프레임

결과(OUTPUT) :
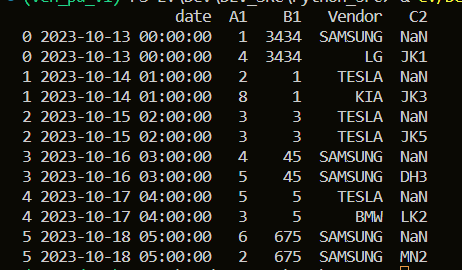
2. 이슈사항
중복 데이터 확인: 두 데이터프레임이 날짜 및 시간이 동일한 열을 포함하고 있으므로, 병합 후 중복 데이터가 발생할 수 있습니다. drop_duplicates 메소드를 사용하여 중복을 제거할 수 있습니다.
# 기존 코드에 중복 제거 추가 merged_df = pd.concat([df1, df2]).drop_duplicates().sort_values(by='date')컬럼 일치성 확인: 두 데이터프레임의 컬럼이 일부 다릅니다. df1은 'C2' 컬럼이 없으므로, 병합 후 'C2' 컬럼에는 NaN 값이 들어갈 것입니다. 필요에 따라 이를 처리하는 로직을 추가할 수 있습니다.
날짜 형식 일관성: 날짜 및 시간 데이터는 pd.to_datetime을 사용하여 일관된 형식으로 변환되어 있습니다. 이는 데이터 처리의 정확성과 효율성을 보장합니다.
Pandas를 사용하여 다른 형식의 데이터프레임을 날짜 및 시간을 기준으로 효율적으로 병합하는 방법을 배웠습니다. 이 방법은 데이터 분석에서 자주 마주치는 시나리오로, 이를 통해 데이터 전처리 과정을 간소화하고 분석의 정확성을 높일 수 있습니다.
마무리
- 이번 포스팅은 시계열 데이터프레임의 병합(Merge) 에 대해 알아봤습니다.
궁금한 사항은 댓글을 통해서 남겨 주시면 답변 드리겠습니다.
감사합니다.
728x90
반응형
'PYTHON 파이썬 > PANDAS(판다스)' 카테고리의 다른 글
| Pandas 데이터 처리: 특정 문자열 조건 탐색(df.apply(),lambda) (0) | 2024.02.02 |
|---|---|
| 판다스 시작하기: 데이터 분석의 첫걸음 (0) | 2024.01.27 |
| [Python Pandas] 데이터 프레임에서 특정 열 삭제 및 에러 대처 하기 (0) | 2024.01.25 |
| [병합/Merge] 2개의 데이터의 특정 열의 이름과 값이 같은 행 병합 (1) | 2024.01.07 |
| [병합/Merge] 열과 행이 다르고, 특정 열의 이름과 값이 같은 다른 데이터프레임 병합 (1) | 2024.01.06 |